
Operational
Resilience
A perfect backup still means an outage if a change takes the business offline. Operational resilience is the other half of the picture - keeping systems running and correct through every change. It is what makes data resilience worth having.
What is operational resilience?
Operational resilience is an organization's ability to keep delivering its critical business services without interruption - even while changes, failures, and disruptions occur. In IT terms, it means systems stay available and behave correctly through patches, updates, configuration changes, and AI-initiated actions.
It is distinct from data resilience, which protects the data itself - backup, integrity, recoverability. Operational resilience protects the running of the business. You need both: a flawless backup does not prevent an outage.
Two pillars, one resilient enterprise
Most organizations have invested heavily in data resilience - backup, replication, disaster recovery. But that is only one pillar. If a change takes systems offline, you are still down, backup or not. Operational resilience is the second pillar - and like any two load-bearing pillars, the structure only stands when both are in place. Remove either one and the building collapses.
Together, the two halves form a single, complete posture we call Operational Data Resilience: the business stays running and its data stays recoverable - at the same time, through every change.
- Operational Keeps the business running - uptime, correct behavior, fast recovery through change.
- Data Keeps the data recoverable - backup, cryptographic integrity, restore.

Two pillars, two jobs - here's what each one focuses on.
| Operational Resilience | Data Resilience | |
|---|---|---|
| What it protects | The running of the business | The data itself |
| Question it answers | "Does the business keep running?" | "Is my data safe and recoverable?" |
| Focus areas | Change validation, behavior, dependencies, recovery readiness | Backup, replication, cryptographic integrity, restore |
| Primary threat | A bad change taking systems offline | Loss, corruption, or ransomware |
| Keystone gates | G2 windows - G5 dependencies - G6 behavior - G8 recovery | G1 backup & baseline - G4 integrity (BLAKE3) |
| If it's the only one you have | An outage is still possible - despite good backups | Data is safe - but an outage still stops the business |
Hover each option to see what it actually covers
Only with both - Operational Data Resilience - does the structure stand: the business keeps running and its data stays recoverable, through every change. AuthorityGate Keystone is built to deliver both pillars from a single platform.
The thing that breaks production is change
of unplanned outages are caused by operational changes - not cyberattacks.
is how fast agentic AI now makes changes - far faster than human review can keep up.
of Fortune 1000s, by 2028 (Gartner), will worry about losing control of AI agents.
The CrowdStrike outage was not an attack - it was an update. A single operational change crossed the gap between approval and production unvalidated, and the business impact was global. Operational resilience is the discipline of making sure that can't happen: every change proven safe to run before it executes, at the speed the change is made.
Anatomy of a change-induced outage
Outages rarely begin with malice. They begin with a routine, approved change that no one re-checked at the moment it actually ran:
- 1 A change is approved at a point in time - reviewed against the environment as it looked then.
- 2 The gap opens. Between approval and deployment the change mutates, a dependency shifts, a vendor auto-update lands, or an AI agent or pipeline pushes it - and no one re-validates against the environment as it looks now.
- 3 It lands in production unvalidated and behaves differently than anyone expected in your specific estate.
- 4 The impact cascades through dependencies - one "safe" change quietly takes another service offline.
- 5 The scramble to recover begins - under pressure, often without a rehearsed rollback, while the business is already down.
The cost is more than downtime
When a critical service stops, the meter runs on every front at once: lost revenue and missed transactions, SLA penalties and contractual exposure, emergency engineering hours, and the slower-burning costs of eroded customer trust and reputational damage. Operational resilience has moved from an IT concern to a board-level and regulatory one - the ability to keep delivering critical services through disruption is now something organizations are expected to demonstrate, not just hope for.
Detect-and-recover is not resilience
Most tooling watches production and tells you after something has already broken - then helps you clean it up. That is monitoring and recovery, not resilience. By the time an alert fires, the outage has happened. True operational resilience moves the check left of production: it validates a change against your known-good baseline, notifies the right people the moment one is detected, and keeps a rehearsed path back to a known-good state for anything that doesn't hold up. The goal is not faster cleanup - it is fewer outages.
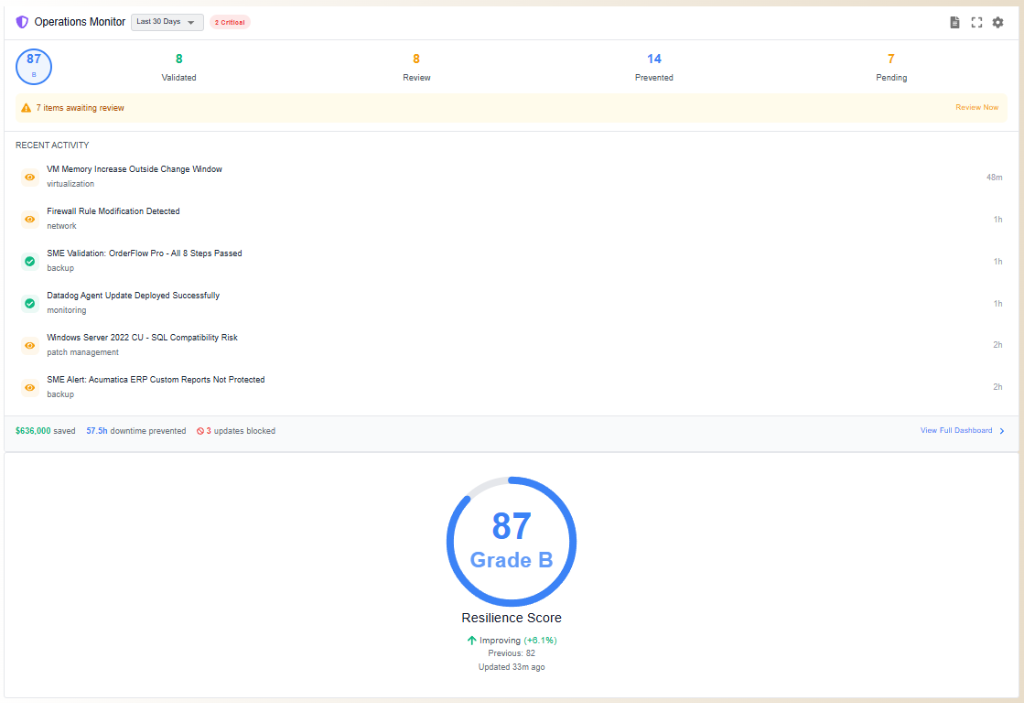
Operational resilience, gate by gate
Four of Keystone's eight validation gates exist specifically to protect uptime - proving a change is operationally safe before it runs, and that recovery is ready if it isn't.
Maintenance-Window Enforcement
Changes only execute inside approved windows and never during org-wide freezes - so a change never lands when no one is ready to respond.
Dependency Health Checks
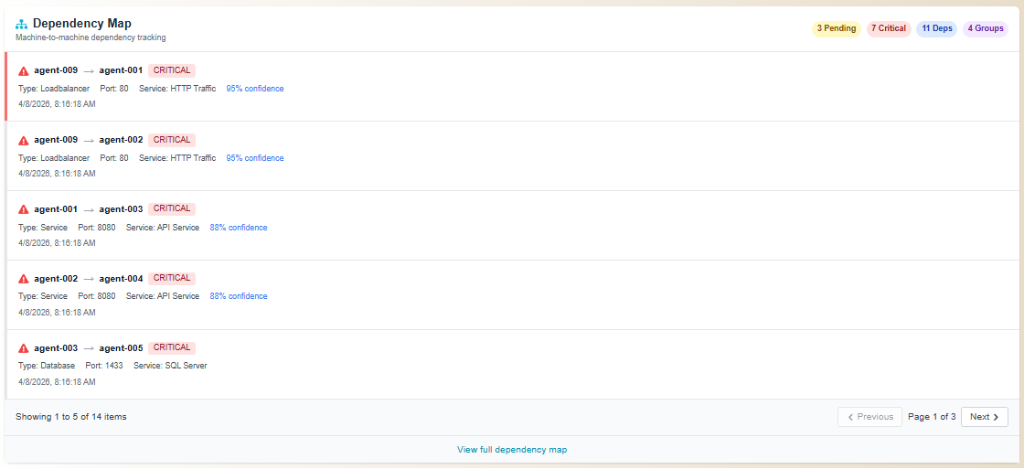
Validates upstream and downstream dependencies so a "safe" change to one service cannot silently take another offline.
Behavioral Resilience (Block Stack)
Runs the change in a lower environment that mirrors production and compares behavior against a baseline - catching CrowdStrike-class failures before they spread.
Recovery Readiness
Confirms a tested rollback and recovery plan exists and is ready before any change is cleared to execute. Resilience is proven, not assumed.
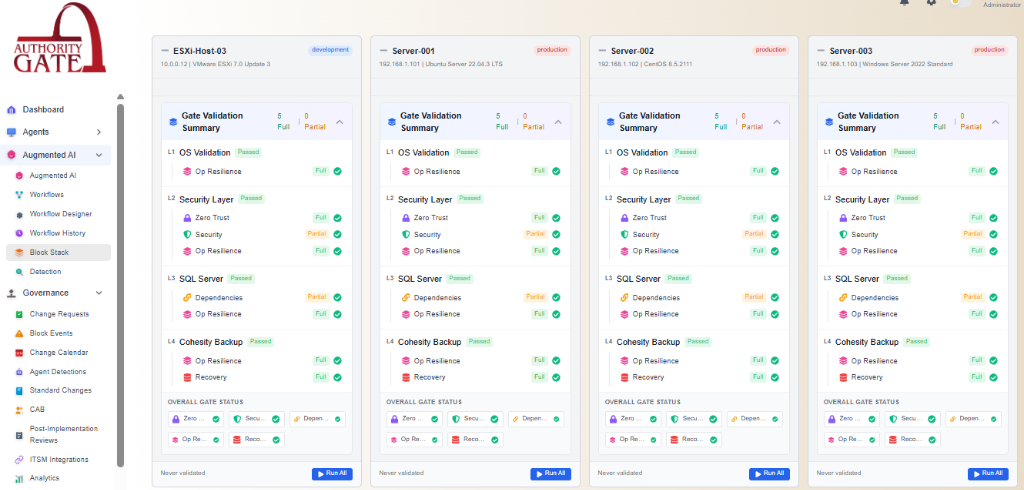
See how all eight gates work together in Change Validation.
Resilience needs a definition of "correct." Known-Good Mode supplies it.
You can't tell whether a change is safe to run unless you know what "running correctly" looks like. Operational resilience is only as strong as the reference it measures against - and that reference is your known-good baseline: the verified, healthy state of your systems in your estate, captured for your real configuration and dependencies - not a vendor's lab default.
Known-Good Mode captures and verifies that baseline at Gate 1. Operational resilience then enforces it on every change: Gate 6 runs the change in a production-mirroring Block Stack and compares its behavior against the baseline, and Gate 8 keeps a tested path back to it. One supplies the truth; the other defends it.
- Known-Good Defines what correct behavior is for your environment.
- Operational Proves every change still matches it, before production.
- Together Deviation from known-good becomes the signal to notify, validate, and - if needed - recover.

What happens the moment Keystone detects a change
Keystone isn't hunting for viruses to quarantine - it's detecting change: any change to your environment, whether it's unwanted, unvalidated, or one that turns out to break something. The instant a change is detected, two things happen at once - the named SME and/or AuthorityGate Director is notified, and Keystone runs its validation procedure to confirm the business, servers, and environment are still operational. What happens next depends entirely on that result.
Unwanted
Unauthorized / drift
A change with no approved record, or configuration drift no one logged. Keystone surfaces it and raises it for review - change is never silent or unseen.
Unvalidated
Skipped the gates
A vendor auto-update, an AI-agent action, or a manual hotfix that never went through the pipeline. Keystone detects it and runs it through validation before it's trusted.
Breaking
Fails validation
A change whose validation shows the environment is no longer behaving correctly against your known-good baseline - the case that triggers recovery.
The flow: detect -> notify & validate -> recover or accept
- 1 Detect. Keystone identifies the change - from a human, a pipeline, a vendor auto-update, or an AI agent - and measures its behavior against your known-good baseline.
- 2 Notify. The named SME and/or AuthorityGate Director is alerted immediately, with the change details, an AI-synthesized risk score, and full gate context (Gate 7).
- 3 Validate - in parallel. At the same time, Keystone runs its validation procedure (Gate 6 behavioral checks, dependency health) to confirm the business, servers, and environment are still operational.
If validation fails
Recover or revert
The SME / AuthorityGate Director is presented with response options to recover or revert the change. In many situations this is fully automated - an immediate rollback to your known-good state - so business continuity is preserved without waiting on a human.
If validation passes
Accept & optionally promote
The same response options are offered - and because the environment is confirmed still operational, the SME / AuthorityGate Director can update the known-good configuration to adopt the change as the new validated baseline.
Recorded throughout. Every detection, notification, AI assessment, validation result, human decision, and rollback is written to a tamper-evident audit trail - so accountability survives at machine speed.
Operational resilience, answered
What is operational resilience?
Operational resilience is an organization's ability to keep delivering its critical business services without interruption - even while changes, failures, and disruptions occur. In an IT context it means systems stay available and behave correctly through patches, updates, configuration changes, and AI-initiated actions. It is distinct from data resilience: data resilience protects the data itself (backup, integrity, recoverability), while operational resilience protects the running of the business. You need both - a perfect backup does not prevent an outage.
How is operational resilience different from data resilience?
Data resilience answers "is my data safe and recoverable?" - it covers backups, replication, cryptographic integrity, and restore. Operational resilience answers "does the business keep running?" - it covers uptime, correct behavior, and fast recovery when a change goes wrong. The two complete each other. If a bad change takes your systems offline, a flawless backup still leaves you with an outage; if your systems stay up but your data is corrupted, you are still in an incident. AuthorityGate Keystone is built to deliver both: operational resilience through pre-deployment behavioral validation, and data resilience through backup verification and integrity checks.
Why is operational resilience critical now?
Because the dominant cause of downtime is change, and change is accelerating. Roughly 80% of unplanned outages are caused by operational changes - patches, updates, and configuration changes - rather than cyberattacks. Now that agentic AI systems and CI/CD pipelines push changes at machine speed, the volume and velocity of change that can break production has multiplied, while human review still runs at human speed. Operational resilience is the discipline of validating that every change is safe to run before it reaches production, at the same speed the change is made.
How does Keystone deliver operational resilience?
Keystone validates the operational safety of every change before it executes. Gate 2 enforces approved maintenance windows; Gate 5 checks service dependencies; Gate 6 runs the change in a production-mirroring lower environment (Block Stack) and compares observed behavior against a baseline to catch anomalies; and Gate 8 confirms a tested rollback and recovery plan is ready. Together these gates ensure a change cannot take the business offline - and that if anything does go wrong, recovery is immediate and rehearsed. Paired with Keystone's backup and integrity verification, this completes a resilience posture that covers both uptime and data.
How does operational resilience relate to Known-Good Mode?
They are two halves of the same control. Known-Good Mode defines what "running correctly" looks like for your environment by capturing and verifying a known-good baseline (Gate 1) - your real configuration, dependencies, and behavior, not a vendor's lab default. Operational resilience then enforces that definition on every change: Gate 6 measures the change's behavior against the baseline, and Gate 8 keeps a tested path back to it. Without a known-good baseline you have nothing trustworthy to measure a change against; without operational resilience the baseline is never enforced. Deviation from known-good is precisely the signal Keystone uses to notify the SME/AuthorityGate Director, validate that the environment is still operational, and - if it isn't - recover or revert.
What happens when Keystone detects an unwanted or unvalidated change?
Both are detected and surfaced - change is never silent. Unwanted changes are those with no approved record or configuration drift no one logged; unvalidated changes are vendor auto-updates, AI-agent actions, or manual hotfixes that skipped the pipeline. The moment one is detected, Keystone notifies the named SME and/or AuthorityGate Director with full context and an AI-synthesized risk score (Gate 7), and in parallel runs its validation procedure to confirm the business, servers, and environment are still operational. If validation passes, the change can be accepted - and the SME/Director may update the known-good configuration to adopt it as the new baseline. If validation fails, they are given options to recover or revert, which in many cases is fully automated. Every step is written to a tamper-evident audit trail.
What does Keystone do when a change would break production?
When a detected change fails validation - its behavior no longer matches your known-good baseline, or a dependency is impacted - Keystone presents the named SME and/or AuthorityGate Director with response options to recover or revert the change. In many situations this is fully automated: an immediate rollback to your verified known-good state, so business continuity is preserved without waiting on a human. This isn't quarantining a virus - it's reverting an operational change that didn't hold up. If validation instead passes, the same options are offered, and the SME/Director may promote the change by updating the known-good configuration. Detection, the validation result, every human decision, and any rollback are all logged to a tamper-evident audit trail.
Make resilience operational, not just theoretical
Operational resilience is one capability of AuthorityGate Keystone. Join the invitation-only Founding Members Early Access Program and close the gap between approval and production.